Database Load Balancing (PREMIUM SELF)
Introduced in GitLab Premium 9.0.
Distribute read-only queries among multiple database servers.
Overview
Database load balancing improves the distribution of database workloads across multiple computing resources. Load balancing aims to optimize resource use, maximize throughput, minimize response time, and avoid overload of any single resource. Using multiple components with load balancing instead of a single component may increase reliability and availability through redundancy. Wikipedia article
When database load balancing is enabled in GitLab, the load is balanced using a simple round-robin algorithm, without any external dependencies such as Redis. Load balancing is not enabled for Sidekiq as this would lead to consistency problems, and Sidekiq mostly performs writes anyway.
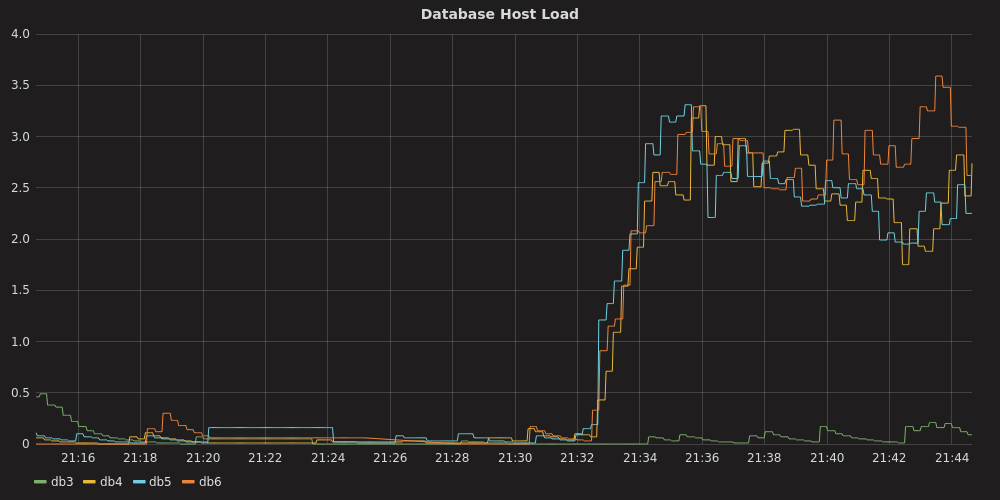
In the following image, you can see the load is balanced rather evenly among
all the secondaries (db4, db5, db6). Because SELECT queries are not
sent to the primary (unless necessary), the primary (db3) hardly has any load.
Requirements
For load balancing to work you will need at least PostgreSQL 11 or newer, MySQL is not supported. You also need to make sure that you have at least 1 secondary in hot standby mode.
Load balancing also requires that the configured hosts always point to the primary, even after a database failover. Furthermore, the additional hosts to balance load among must always point to secondary databases. This means that you should put a load balancer in front of every database, and have GitLab connect to those load balancers.
For example, say you have a primary (db1.gitlab.com) and two secondaries,
db2.gitlab.com and db3.gitlab.com. For this setup you will need to have 3
load balancers, one for every host. For example:
-
primary.gitlab.comforwards todb1.gitlab.com -
secondary1.gitlab.comforwards todb2.gitlab.com -
secondary2.gitlab.comforwards todb3.gitlab.com
Now let's say that a failover happens and db2 becomes the new primary. This means forwarding should now happen as follows:
-
primary.gitlab.comforwards todb2.gitlab.com -
secondary1.gitlab.comforwards todb1.gitlab.com -
secondary2.gitlab.comforwards todb3.gitlab.com
GitLab does not take care of this for you, so you will need to do so yourself.
Finally, load balancing requires that GitLab can connect to all hosts using the same credentials and port as configured in the Enabling load balancing section. Using different ports or credentials for different hosts is not supported.
Use cases
- For GitLab instances with thousands of users and high traffic, you can use database load balancing to reduce the load on the primary database and increase responsiveness, thus resulting in faster page load inside GitLab.
Enabling load balancing
For the environment in which you want to use load balancing, you'll need to add
the following. This will balance the load between host1.example.com and
host2.example.com.
In Omnibus installations:
-
Edit
/etc/gitlab/gitlab.rband add the following line:gitlab_rails['db_load_balancing'] = { 'hosts' => ['host1.example.com', 'host2.example.com'] } -
Save the file and reconfigure GitLab for the changes to take effect.
In installations from source:
-
Edit
/home/git/gitlab/config/database.ymland add or amend the following lines:production: username: gitlab database: gitlab encoding: unicode load_balancing: hosts: - host1.example.com - host2.example.com -
Save the file and restart GitLab for the changes to take effect.
Service Discovery
Introduced in GitLab Premium 11.0.
Service discovery allows GitLab to automatically retrieve a list of secondary
databases to use, instead of having to manually specify these in the
database.yml configuration file. Service discovery works by periodically
checking a DNS A record, using the IPs returned by this record as the addresses
for the secondaries. For service discovery to work, all you need is a DNS server
and an A record containing the IP addresses of your secondaries.
To use service discovery you need to change your database.yml configuration
file so it looks like the following:
production:
username: gitlab
database: gitlab
encoding: unicode
load_balancing:
discover:
nameserver: localhost
record: secondary.postgresql.service.consul
record_type: A
port: 8600
interval: 60
disconnect_timeout: 120Here, the discover: section specifies the configuration details to use for
service discovery.
Configuration
The following options can be set:
| Option | Description | Default |
|---|---|---|
nameserver |
The nameserver to use for looking up the DNS record. | localhost |
record |
The record to look up. This option is required for service discovery to work. | |
record_type |
Optional record type to look up, this can be either A or SRV (GitLab 12.3 and later) | A |
port |
The port of the nameserver. | 8600 |
interval |
The minimum time in seconds between checking the DNS record. | 60 |
disconnect_timeout |
The time in seconds after which an old connection is closed, after the list of hosts was updated. | 120 |
use_tcp |
Lookup DNS resources using TCP instead of UDP | false |
If record_type is set to SRV, GitLab will continue to use a round-robin algorithm
and will ignore the weight and priority in the record. Since SRV records usually
return hostnames instead of IPs, GitLab will look for the IPs of returned hostnames
in the additional section of the SRV response. If no IP is found for a hostname, GitLab
will query the configured nameserver for ANY record for each such hostname looking for A or AAAA
records, eventually dropping this hostname from rotation if it can't resolve its IP.
The interval value specifies the minimum time between checks. If the A
record has a TTL greater than this value, then service discovery will honor said
TTL. For example, if the TTL of the A record is 90 seconds, then service
discovery waits at least 90 seconds before checking the A record again.
When the list of hosts is updated, it might take a while for the old connections
to be terminated. The disconnect_timeout setting can be used to enforce an
upper limit on the time it takes to terminate all old database connections.
Some nameservers (like Consul) can return a truncated list of hosts when
queried over UDP. To overcome this issue, you can use TCP for querying by setting
use_tcp to true.
Forking
NOTE: Starting with GitLab 13.0, Puma is the default web server used in GitLab all-in-one package based installations as well as GitLab Helm chart deployments.
If you use an application server that forks, such as Unicorn, you have to update your Unicorn configuration to start service discovery after a fork. Failure to do so leads to service discovery only running in the parent process. If you are using Unicorn, then you can add the following to your Unicorn configuration file:
after_fork do |server, worker|
defined?(Gitlab::Database::LoadBalancing) &&
Gitlab::Database::LoadBalancing.start_service_discovery
endThis ensures that service discovery is started in both the parent and all child processes.
Balancing queries
Read-only SELECT queries balance among all the secondary hosts.
Everything else (including transactions) executes on the primary.
Queries such as SELECT ... FOR UPDATE are also executed on the primary.
Prepared statements
Prepared statements don't work well with load balancing and are disabled automatically when load balancing is enabled. This should have no impact on response timings.
Primary sticking
After a write has been performed, GitLab sticks to using the primary for a certain period of time, scoped to the user that performed the write. GitLab reverts back to using secondaries when they have either caught up, or after 30 seconds.
Failover handling
In the event of a failover or an unresponsive database, the load balancer tries to use the next available host. If no secondaries are available the operation is performed on the primary instead.
If a connection error occurs while writing data, the operation is retried up to 3 times using an exponential back-off.
When using load balancing, you should be able to safely restart a database server without it immediately leading to errors being presented to the users.
Logging
The load balancer logs various events in
database_load_balancing.log, such as
- When a host is marked as offline
- When a host comes back online
- When all secondaries are offline
- When a read is retried on a different host due to a query conflict
The log is structured with each entry a JSON object containing at least:
- An
eventfield useful for filtering. - A human-readable
messagefield. - Some event-specific metadata. For example,
db_host - Contextual information that is always logged. For example,
severityandtime.
For example:
{"severity":"INFO","time":"2019-09-02T12:12:01.728Z","correlation_id":"abcdefg","event":"host_online","message":"Host came back online","db_host":"111.222.333.444","db_port":null,"tag":"rails.database_load_balancing","environment":"production","hostname":"web-example-1","fqdn":"gitlab.example.com","path":null,"params":null}Handling Stale Reads
Introduced in GitLab Premium 10.3.
To prevent reading from an outdated secondary the load balancer checks if it is in sync with the primary. If the data is determined to be recent enough the secondary is used, otherwise it is ignored. To reduce the overhead of these checks we only perform these checks at certain intervals.
There are three configuration options that influence this behavior:
| Option | Description | Default |
|---|---|---|
max_replication_difference |
The amount of data (in bytes) a secondary is allowed to lag behind when it hasn't replicated data for a while. | 8 MB |
max_replication_lag_time |
The maximum number of seconds a secondary is allowed to lag behind before we stop using it. | 60 seconds |
replica_check_interval |
The minimum number of seconds we have to wait before checking the status of a secondary. | 60 seconds |
The defaults should be sufficient for most users. Should you want to change them
you can specify them in config/database.yml like so:
production:
username: gitlab
database: gitlab
encoding: unicode
load_balancing:
hosts:
- host1.example.com
- host2.example.com
max_replication_difference: 16777216 # 16 MB
max_replication_lag_time: 30
replica_check_interval: 30